Nepal


OpenAI, the ChatGPT developer, announced the next version of its language model GPT-4 on Tuesday which the company says is “the latest milestone in its effort in scaling up deep learning”.
Surprisingly, the powerful GPT-4 was hiding in plain sight for more than a month now in the form of Bing CHAT, the AI-powered search engine from Microsoft, limited to a few million beta testers including NepalMinute.
In the announcement, the company claimed the new version to be superior to the previous iteration GPT-3 and 3.5—powering the ChatGPT—in every metric.
The company announced that the version of GPT is multimodal, meaning it can take inputs in text and even in pictorial form to produce a text-based output. For instance, one can upload a picture of a math problem and get the answer in seconds.
For now, the company says, it is releasing the product without the capability to process the image to a limited number of users in its monthly subscription package ‘ChatGPT Plus’ and software developers in the ‘API waitlist’.
Or get access to it through Bing CHAT, which Microsoft confirmed on Tuesday has GPT-4 under the hood.
So, what are the improvements in this sentient-looking AI chatbot?
Improvements
GPT-4 can generate textual answers by accepting images or texts as input, unlike its predecessor which only accepted text inputs.
Image processing is still in research preview, the company hopes to release it at a later date. But in the test runs, the company says the AI model was able to develop a similar ‘chain of thoughts’ as in the text models.
The company claimed the AI engine has a larger language model without giving the actual figure, for comparison GPT-3 had over 175 billion parameters. Parameters are like the knowledge base of the neural network analogous to variables in a mathematical equation; the higher the better.
With this, GPT-4 is able to generate about 25,000 words in a given text over eight times more than the capability of ChatGPT.
OpenAI claims the new version performs at the “human level” on various professional and academic benchmarks. The company said the language model passed several tests scoring marks comparable to the top 90 per cent in several cases.
For instance, it passed a simulated bar exam with a score “around the top 10% of test takers; in contrast, GPT-3.5’s score was around the bottom 10%.”
And in a Graduate Record Examination (GRE) Verbal, it scored 169/170 which is the 99 percentile.
Completing the training in Microsoft’s Azure cloud infrastructure nearly 6 months ago, OpenAI has been tuning the AI model for “factuality, steerability, and refusing to go outside of guardrails” since then.
In OpenAI’s words: “GPT-4 is more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5.”
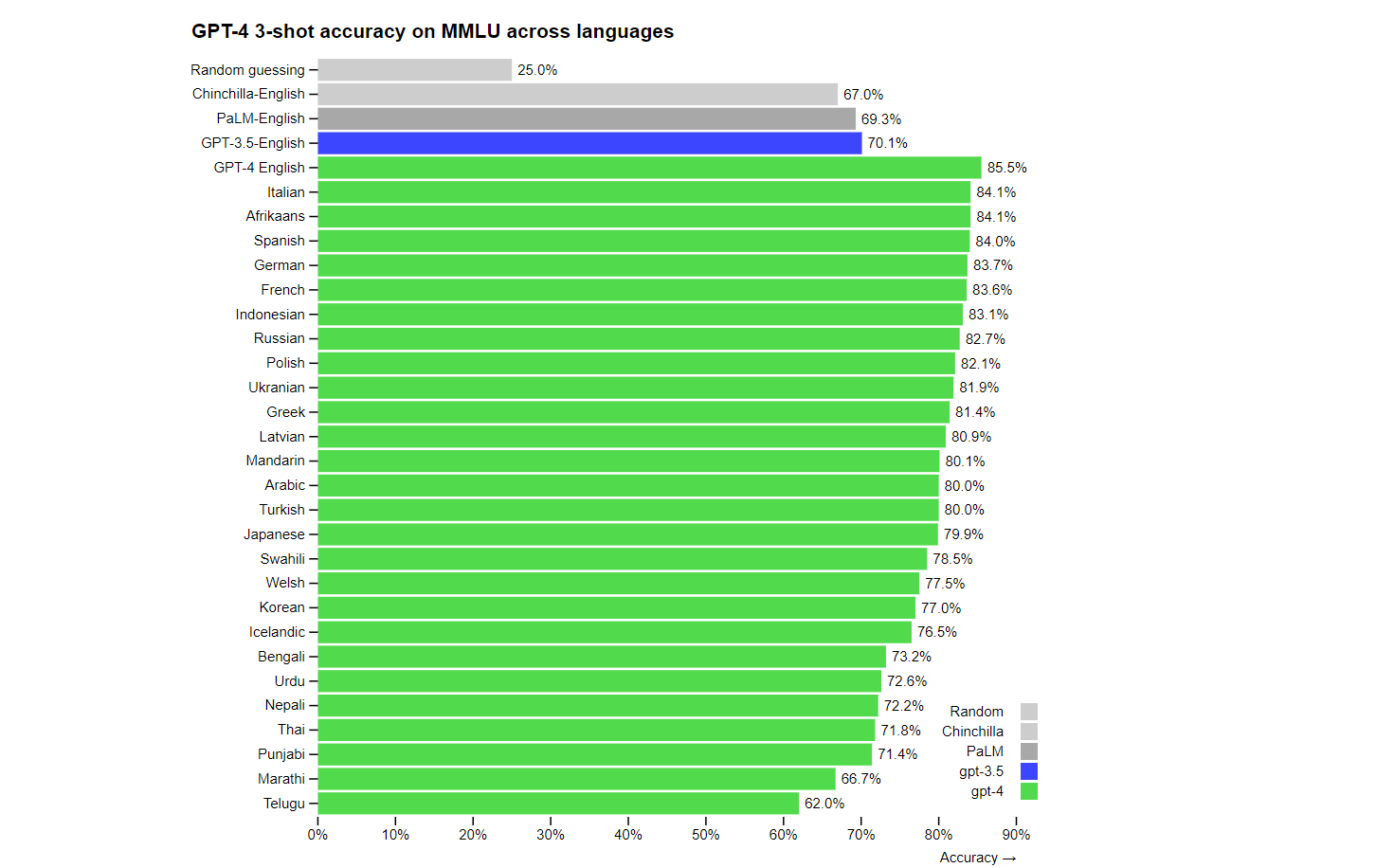
The model also has substantially better multi-language performance outperforming every other language model in existence, as per the company’s claim.
When tested in Nepali, which was one of the 26 different languages it was tested on, GPT-4 had an accuracy of over 72 per cent.
Limitations

As is, the main limitation of any sophisticated AI language model is that it can go off track in numerous edge-case scenarios.
Although scoring 40 per cent higher than GPT-3.5 on the company’s adversarial factuality evaluations, the company in the research paper writes: “It still is not fully reliable (it “hallucinates” facts and makes reasoning errors).”
“Great care should be taken when using language model outputs, particularly in high-stakes contexts,” it writes.
Also read: Do you know Bing CHAT brings you real-time information on the go?
Also read: Nepal Police calms fears over escalating AI-based cybercrimes


